# Lec 06 - Advanced Processor
In this lecture, we will exploit different methods to extract even more performance from the pipelined processor that we built in [Lec 05](https://wenbo-notes.gitbook.io/ddca-notes/lec/lec-05-the-pipelined-processor)!
## Branch Prediction
An ideal pipelined processor would have a CPI of 1. The branch misprediction penalty is a major reason of increased CPI. As pipelines get **deeper**, branches are resolved later in the pipeline. Thus, the **branch misprediction penalty** gets **larger** because all the instructions issued after the mispredicted branch must be **flushed**. To address this problem, most pipelined processors use a **branch predictor/prediction** to guess whether the branch should be taken.
In Lec 05, the way we [handle the control hazard](https://wenbo-notes.gitbook.io/ddca-notes/lec-05-the-pipelined-processor#handle-control-hazards) is to simply predict that branches are never taken.
{% hint style="success" %}
**Branch misprediction penalty** is the **flushing** of all the instructions issued after the mispredicted branch.
{% endhint %}
### Static Branch Prediction
The simplest form of branch prediction checks the **direction** of the branch and predicts that [backward branches](#backward-branches) are taken and [forward branches](#forward-branches) are not.
#### Forward Branches
These are the branches that occur at the **beginning** of a loop to check a condition and **branch past the loop** when the condition is no longer met (e.g., in *for* and *while* loops). Loops tend to execute many times, so these forward branches are **usually not taken**.
{% code lineNumbers="true" %}
```riscv
Loop: beq s1, s2, Out
1nd loop instr
.
.
.
last loop instr
j Loop
Out: fall out instr
```
{% endcode %}
#### Backward Branches
These are the branches that occur when a program reaches the **end** of a loop and **branches back to repeat the loop** (e.g., *do-while* loop). Again, because loops tend to execute many times, these backward branches are **usually taken**.
{% code lineNumbers="true" %}
```riscv
Loop: 1st loop instr
2nd loop instr
.
.
.
last loop instr
bne s1, s2, Loop
fall out instr
```
{% endcode %}
### Dynamic Branch Prediction
However, branches, especially forward branches, are difficult to predict without knowing more about the specific program. Therefore, most processors use **dynamic branch predictors/predictions**, which use the history of program execution to guess whether a branch should be taken.
Dynamic branch predictors maintain a table of the last several hundred (or thousand) branch instructions that the processor has executed. The table, called a **branch target buffer**, includes the destination of the branch and a history of whether the branch was taken.
To see it clearly, consider the following loop. The loop repeats 10 times, and the branch out of the loop (`bge s0, t0, done`) is taken only on the last iteration.
{% code lineNumbers="true" %}
```riscv
addi s1, zero, 0 # s1 = sum = 0
addi s0, zero, 0 # s0 = i = 0
addi t0, zero, 10 # to = 10
for:
bge s0, t0, done # i >= 10?
add s1, s1, s0, # sum = sum + i
addi s0, s0, 1 # i = i + 1
j for # repeat loop
done:
```
{% endcode %}
#### One-bit Dynamic Branch Predictor
A **one-bit dynamic branch predictor** remembers whether the branch was taken the **last time** and predicts that it will do the same thing the next time.
While the loop is repeating, it remembers that the `bge` **was not taken last time** and predicts that it should not be taken next time. This is a **correct prediction** until the last branch of the loop, when the branch does get taken. Unfortunately, if the loop is run again, the branch predictor **remembers that the last branch was taken**. Therefore, it **incorrectly predicts** that the branch should be taken when the loop is first run again.
In summary, a **one-bit dynamic branch predictor** mispredicts the **first** and **last** branches of a loop. And its accuracy is 80% if the loop repeats 10 times. In a loop with N iterations, the accuracy is
$$
\text{accuracy}=\frac{N-2}{N}\times100%
$$
{% hint style="warning" %}
The accuracy of 80% doesn't apply to all cases! It is the accuracy only when the loop repeats 10 times!
{% endhint %}
Implement a 1-bit branch predictor
{% hint style="info" %}
In [Mach-V](https://mendax1234.github.io/Mach-V/), I am currently working on the branch prediction feature. This section only explains the method provided by the prof.
{% endhint %}
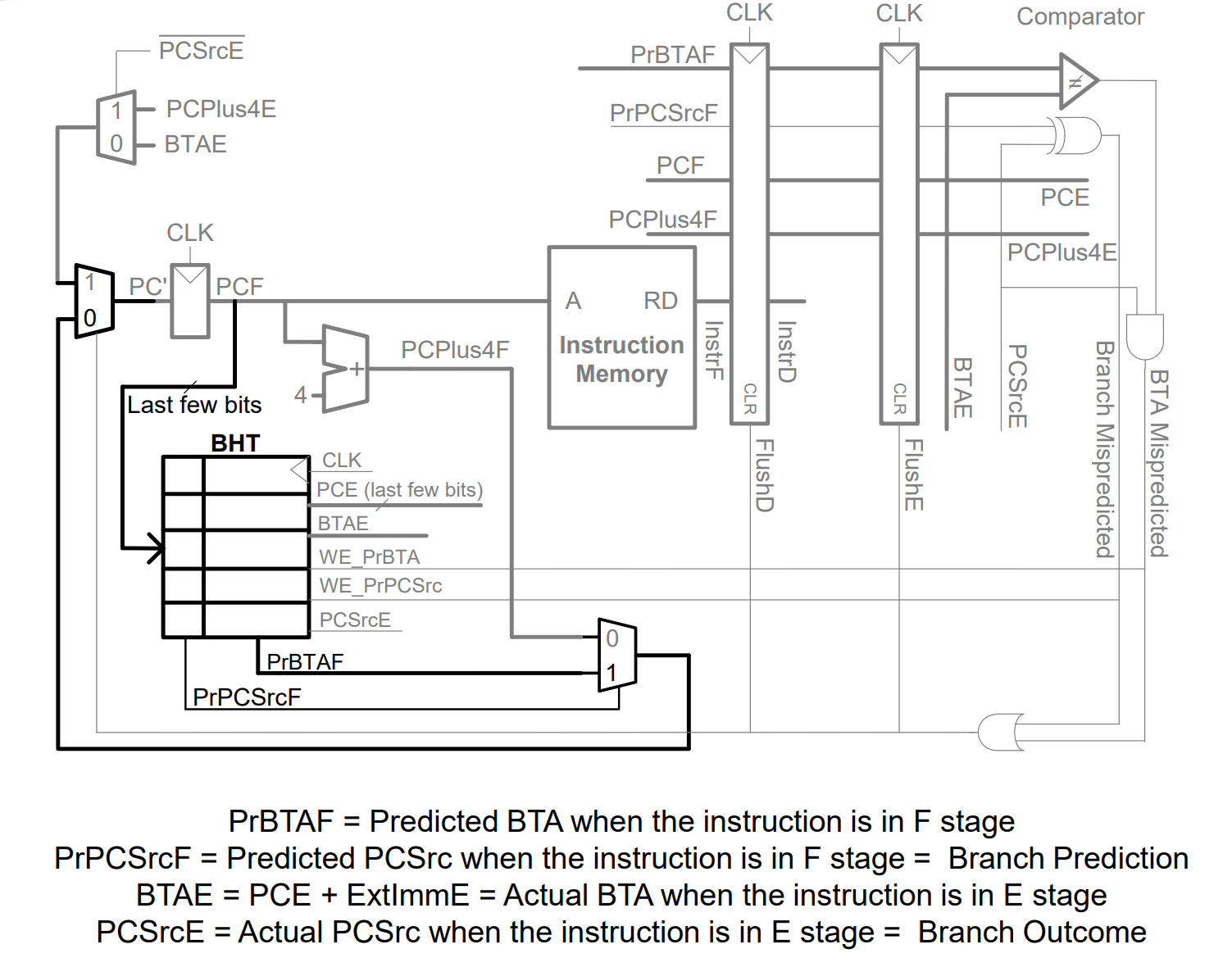
This design acts as a hybrid [**Branch History Table**](#user-content-fn-1)[^1] (BHT) and **Branch Target Buffer** (BTB). It uses a "cache-like" structure to remember the outcome and target of the most recent branch at a specific PC index.
**1. Prediction (Fetch Stage)**
* Indexing: The predictor uses the Lower Significant Bits (LSB) of the current `PCF` (e.g., bits `[4:2]`) to index the table.
* Lookup: It reads the entry at that index to retrieve:
* `PrPCSrcF` (Predicted Direction): Should we branch? (1 = Taken, 0 = Not Taken).
* `PrBTAF` (Predicted Target): Where do we jump?
* Action: If `PrPCSrcF == 1`, the PC Mux immediately updates `PC` to `PrBTAF` (predicting "Taken") so the next instruction at the BTA will be fetched during the next clock cycle.
**2. Validation (Resolution Stage)**
* Comparison: The processor waits until the branch resolves (in the Execute or Memory stage) to check two things:
1. Direction Check: Did we guess Taken/Not Taken correctly? (`Actual_PCSrc` XOR `Predicted_PCSrc`).
2. Target Check: Did we jump to the correct address? (`Actual_BTA` != `Predicted_BTA`).
* Misprediction Signal: If the check fails, either the `Branch_Mispredicted` signal goes high or `BTA_Mispredicted` goes high.
**3. Recovery & Update (Writeback)**
* Flush: If mispredicted, the pipeline flushes instructions fetched from the wrong path (`FlushD`, `FlushE`).
* Correction: The PC is reset to the correct address (`BTAE` if taken, `PCE+4` if not).
* Training: The BHT is updated (Written) with the *correct* information (`PCSrc`, `BTA`) for that PC index so the prediction is accurate next time.
{% hint style="danger" %}
This implementaion targets the [first version](https://wenbo-notes.gitbook.io/ddca-notes/lec/lec-03-risc-v-isa-and-microarchitecture#single-cycle-processor-with-control) of the RISC-V microarchitecture introduced in Lec 03. For the one that is applicable for the latest microarchitecture, please wait for Mach-V!
{% endhint %}
> Why not use `InstrF` to index the BHT?
Indexing the **BHT with `InstrF`** would require placing the BHT **after the instruction memory**, since the instruction should better be fetched and decoded before we know whether it is a branch. This is undesirable because **instruction memory access dominates the Fetch-stage delay**; placing the BHT after it would **lengthen the critical path** and reduce the maximum clock frequency.
Instead, we index the **BHT with `PCF`**. This allows the BHT lookup to occur **in parallel with instruction memory access**, keeping the Fetch-stage critical path short. Although PC-based indexing may cause **aliasing or predictions on non-branch instructions**, this is acceptable because the predictor’s main goal is to **speculatively compute the next PC early**.
**Operation sequence (PC-indexed BHT):**
* In cycle *n*, `PCF` indexes the BHT while the instruction is fetched from instruction memory.
* If the fetched instruction turns out to be a branch, the BHT prediction is already available.
* Based on the prediction, the **next PC** (PC+4 or BTA) is selected for cycle *n+1*.
* If predicted taken, the instruction at the **BTA** is fetched in the next cycle.
#### Two-bit Dynamic Branch Predictor
A **two-bit dynamic branch predictor** can decrease the number of misprediction by having four states: Strongly Taken, Weakly Taken, Weakly Not Taken, and Strongly Not Taken.
Using the same example [above](#dynamic-branch-prediction), when the loop is repeating, it enters the **Strongly Not Taken** state and predicts that the branch should not be taken next time. This is correct until the last branch of the loop, which is taken and moves the predictor to the **Weakly Not Taken** state. When the loop is first run again, the branch predictor **correctly predicts** that the branch should not be taken and reenters the **Strongly Not Taken** state.
In summary, **two-bit dynamic branch predictor** mispredicts **only the last branch of a loop**. Thus, when the loop has N iterations, it has the accuracy of
$$
\text{accuracy}=\frac{N-1}{N}\times100%
$$
#### Branch Delay Slot
In computer architecture, a **delay slot** is an **instruction slot** being executed without the effects of a preceding branch. The instruction in the delay slot will execute even if the preceding branch is taken. Usually, **independent instructions** are inserted into the delay slot. The insertion of the **independent instruction** which is safe to execute irrespective of branch outcome into the branch delay slot is done by the **compiler**.
Self-Diagnostic Quiz
If 5-stage pipelined processor has a branch delay slot of 2, but it commits the branch at WB stage. How many instructions will be flushed if the branch is taken.
***
**Ans**: 2. When branch is commited at the WB stage, in a 5-stage pipelined processor, 4 instructions would have been fetched already. Among these four instructions, 2 are independent instructions inserted into the branch delay slot, which will be executed anyways. Thus, if the branch is taken, 2 instructions will be flushed.
### Speculative Execution
**Speculative execution** is a performance optimization technique where a computer system or CPU performs tasks ahead of time based on a guess, in order to avoid delays.
One good example is the branch prediction we have seen above. Another example will be the **load speculation**.
Self-Diagnostic Quiz
{% hint style="warning" %}
To better understand this quesiton, you may need to read the [out-of-order processor](#out-of-order-processor) part first.
{% endhint %}
The instruction `sw x1, (x2)` followed by `lw x4, (x3)` can be unconditionally reordered, as there is no dependency between them.
***
**Ans**: False. This is because if `x2` and `x3` has the same value, then there will be a dependency between these two instructions and they cannot be reordered unconditionally. But if they don't have the same value, then the `lw` instruction can be scheduled before the store, this is what we called **load speculation**.
Speculative execution must have (hardware/software) mechanisms for
* Checking to see if the guess was correct
* Recovering from the effects of the instructions that were executed speculatively if the guess was incorrect.
## Deep Pipelining
> As we have seen from Lec 01, to increase performance, we would like to **speed up the clock** and/or **reduce the CPI**. For the CPI, we know that **stalling** and **flushing** will both increase the CPI.
As we have seen the technique of pipelining in Lec 05, it can reduce the clock cycle time and thus increase the clock speed. In real world, aside from the [advances in manufacturing](#user-content-fn-2)[^2], the easiest way to speed up the clock is to **chop the pipelines into more stages**. Each stage contains less logic, so it can run faster. Nowadays, 8-20 stages are commonly used.
However, the maximum number of pipeline stages is limited by the pipeline hazards, sequencing overhead, and cost.
More on the Sequence Overhead effect
Ideally, the clock period is determined solely by the [longest combinational logic delay/critical path](https://wenbo-notes.gitbook.io/ddca-notes/lec/lec-02-digital-system-design-and-verilog?q=#critical-path) (e.g., 8ns in our example). However, in reality, hardware registers introduce fixed timing overheads that must be added to every stage. So, to ensure that the data is captured correctly, we must account for:
* $$t\_{CLK\to Q}$$: The time required for data to leave the source register **after** the clock edge.
* $$t\_{setup}$$: The time that the data must be stable at the destination register **before** the next clock edge.
Using the single cycle processor as an example, even with a 8ns propagation delay, the actual critical path will include the overhead. Assuming $$t\_{CLK\to Q} = 1\text{ns}$$ and $$t\_{setup} = 1\text{ns}$$:
This is shown as the figure below
If we split the logic perfectly into two stages ($$8\text{ns} \div 2 = 4\text{ns}$$), the register overhead does not scale down; it applies to every new stage introduced.
This is again shown as the figure below,
In conclusion, while ideal pipelining suggests a $$2\times$$ speedup (reducing 8ns to 4ns), the fixed overhead limits the actual cycle time to 6ns. Therefore, as pipeline depth increases, the accumulated overhead yields diminishing returns on speedup.
## Micro-Operations
> This technique is largerly used in CISC (Complex Instruction Set Computer).
It means that at run time, more **complex instructions** will be **decomposed** into a series of simple instructions called **micro-operations** (micro-ops or $$\mu$$-ops). These micro-operations can be executed on **simple datapaths**.
{% code lineNumbers="true" %}
```
; Using ARM Assembly as an example
; Complex Op
LDR R1, [R2], #4
; Micro-op Sequence
LDR R1, [R2]
ADD R2, R2, #4
```
{% endcode %}
The decoding process is done by the **hardware** and the micro-operations need not even be **valid instructions** in ISA. This will also increase code density, resulting in less IROM usage.
Micro-operations vs. pseudo-instructions
* **Pseudo-instructions**: The assembler splits pseudo-instructions (which are **not valid** instructions in the ISA) into **valid instructions** within the ISA. The instructions to which the pseudo-instruction is split into is **visible** to the programmer.
* **Micro-operations**: In case of micro-operations, the hardware splits the complex instructions (which are **valid instructions** in the ISA) into simple instructions/operations which are **not necessarily within the ISA**. Micro-operations are **invisible** to the programmer.
### Macro-op Fusion
This is exactly the opposite of the micro-operations. We have seen this earlier in [Lec 04](https://wenbo-notes.gitbook.io/ddca-notes/textbook/digital-building-blocks/arithmetic-circuits#macro-op-fusion)!
## Multiple Issue Processors
### Superscalar Processors
A **superscalar processor** issues several instructions at a time, each of which operates on one piece of data. Thus it contains multiple copies of the datapath hardware to execute multiple instructions simultaneously. The figure below shows a block diagram of a two-way superscalar processor that fetches and executes two instructions per cycle.
#### Ideal Case
The ideal case for a two-way superscalar processor is that it can execute exactly two instructions on each cycle. This is shown in the following figure,
For this program, the proecssor has a CPI of 0.5. Designers commonly refer to the reciprocal of the CPI as the **instructions per cycle**, or **IPC**. This processor has an IPC of 2 on this program.
#### Real Case
As we all know, executing many instructions simultaneously is difficult because of dependencies. The following figure shows a pipeline diagram running a a program with [data dependencies](https://wenbo-notes.gitbook.io/ddca-notes/lec-05-the-pipelined-processor#data-hazards). The dependencies in the code are indicated in blue.
* **Cannot issue simultaneously**: The `add` instruction is dependent on `s8`, which is produced by the `lw` instruction, so it cannot be issued at the same time as `lw`.
* **Data Forwarding**: Additionally, the `add` instruction stalls for yet another cycle so that `lw` can forward `s8` to `add` in cycle 5.
* **Data Forwarding**: The other dependencies (between `sub` and `and` based on `s8`, and between `or` and `sw` based on `s11`) are handled by **forwarding** results produced in one cycle to be consumed in the next.
This program requires fives cycles to issue six instructions, for an IPC of $$6\div5=1.2$$.
Parallelism in temporal and spatial form
Recall that parallelism comes in temporal and spatial forms.
* **Pipelining** is a case of temporal parallelism.
* Using **multiple execution units** is a case of spatial parallelism.
**Superscalar processors** exploit **both** forms of parallelism to squeeze out performance far exceeding that of our single-cycle and multicycle processors
### Out-of-Order Processor
To cope with the problem of dependencies, an **Out-of-Order (OoO) processor** looks ahead across many instructions to issue **independent instructions** as rapidly as possible. The instructions can issue in a **different order** than that written by the programmer as long as dependencies[^3] are honored so that the program produces the intended result. This will increase the **Instruction Level Parallelism (ILP)** and thus increasing the **IPC** also.
Consider running the same program [above](#real-case) on a two-way superscalar out-of-order processor. The processor can issue up to two instructions per cycle from anywhere in the program, as long as dependencies are observed. The following figure shows the data dependencies and the operation of the processor.
The constraints on issuing instructions are:
* **Cycle 1**
* The `lw` instruction issues.
* The `add`, `sub`, and `and` instructions are dependent on `lw` by way of `s8`, so they cannot issue yet. However, the `or` instruction is independent, so it also issues.
* **Cycle 2**
* Remember that a two-cycle latency exists between issuing `lw` and a dependent instruction, so `add` cannot issue yet because of the `s8` dependence. `sub` writes `s8`, so it cannot issue before `add`, lest `add` receive the wrong value of `s8`. `and` is dependent on `sub`.
* Only the `sw` instruction issues.
* **Cycle 3**
* On cycle 3, `s8` is available (or, rather, will be when `add` needs it), so the `add` issues. `sub` issues simultaneously, because it will not write `s8` until after `add` consumes (e.g., reads) it.
* **Cycle 4**
* The `and` instruction issues. `s8` is forwarded from `sub` to `and`.
This out-of-order processor issues the six instructions in four cycles, for an IPC of $$6\div4=1.5$$, which is more than the normal superscalar processor we have introduced above. In the real-world out-of-order processor, we will see three data dependencies (we have seen two in the example above):
{% stepper %}
{% step %}
#### Read After Write (RAW)
In the example above, the dependence of `add` on `lw` by way of `s8` is sa **read after write (RAW)** hazard. `add` must not read `s8` until after `lw` has written it. Similarly, the dependence of `sw` on `or` by way of `s11` and of `and` on `sub` by way of `s8` are RAW dependencies.
This is the type of dependency we are accustomed to handling in the [pipelined processor (Lec 05)](https://wenbo-notes.gitbook.io/ddca-notes/lec-05-the-pipelined-processor#data-forwarding). To solve it, we can use
1. the **data forwarding logic** and
2. sometimes the **stalling technique**.
{% endstep %}
{% step %}
#### Write After Read (WAR)
The dependence between `sub` and `add` by way of `s8` is called a **write after read (WAR)** hazard or an **antidependence**. `sub` must not write `s8` before `add` reads `s8`, so that `add` receives the correct value according to the original order of the program.
A WAR hazard is not essential to the operation of the program. It is merely an artifact of the programmer’s choice to use the same register for two unrelated instructions. If the `sub` instruction had written `s3` instead of `s8`, then the dependency would disappear and `sub` could be issued before `add`.
To solve it, we can use the register renaming technique which will be introduced later!
{% endstep %}
{% step %}
#### Write After Write (WAW)
This hazard is not shown in the example above. It is called a **write afte write (WAW)** hazard or an **output dependence**. A WAW hazard occurs if an instruction attempts to write a register after a subsequent instruction has already written it. The hazard would result in the wrong value being written to the register. For example, in the following code, `lw` and `add` both write `s7`. The final value in `s7` should come from `add` according to the order of the program. If an out-of-order processor attempted to execute `add` first and then `lw`, a WAW hazard would occur.
{% code lineNumbers="true" %}
```riscv
lw s7, 0(t3)
add s7, s1, t2
```
{% endcode %}
WAW hazards are not essential either; again, they are artifacts caused by the programmer using the same destination register for two unrelated instructions.
To solve it, we can just **discard** the result of the unwanted instruction. For example, if the `add` instruction were issued first, then the program could eliminate the WAW hazard by discarding the result of the `lw` instead of writing it to `s7`. This is called **squashing** the `lw`.
> If we discard the value of `s7` in the `lw` instruction, why do we still need to execute the `lw`? This is because we want to make sure there won't be a **load access fault**!
Besides discarding, we can also use register renaming to solve this hazard.
{% endstep %}
{% endstepper %}
#### Implementing the Out-of-Order Execution
While the conceptual goal is to increase ILP, the hardware implementation requires a specific structure to ensure correctness. The diagram below illustrates a typical Out-of-Order processor implementation paradigm. It is divided into three distinct phases to balance speed with stability.
{% stepper %}
{% step %}
#### The Front End: In Order Issue
The Instruction Fetch and Decode Unit retrieves instructions and issues them to the "Reservation Stations."
* **Behavior**: This process happens **In-Order**.
* **Reason**: We must issue in program order to correctly identify and track data dependencies (like the RAW hazards mentioned above) before the instructions are scattered to different units. At this stage, if operands are not ready, the instruction is not stalled; it is simply moved to a waiting area.
{% endstep %}
{% step %}
#### The Execution Core: Out-of-Order Execute
Once issued, instructions sit in **Reservation Stations (RS)**. These buffers hold the instruction and wait for pending operands.
* **Behavior**: The **Functional Units (FUs)** (Integer, Floating point, Load/Store) initiate execution **Out-of-Order**. They start exactly when their data is ready, regardless of the original program sequence.
* **The "Red Arrows"** **(Common Data Bus)**: As soon as a Functional Unit finishes, it broadcasts the result:
1. **To Waiting RS**: The result is forwarded immediately to any other Reservation Station waiting for this data (solving RAW hazards without stalling the fetch unit).
2. **To the Commit Unit**: The result is saved for the final update.
{% endstep %}
{% step %}
#### The Back End: In-Order Commit
The **Commit Unit** (often coupled with a **Reorder Buffer** or ROB) collects results from the execution units.
* **Behavior**: It writes results to the architectural registers (the actual programmer-visible state) **In-Order** (program fetch order).
* **Why?**: This is crucial for two reasons:
1. **Precise Exceptions**: If an instruction crashes (e.g., divide by zero), we ensure that only registers from *previous* instructions are updated. We must not accidentally save the result of a "future" instruction that executed early.
2. **Branch Misprediction**: If the processor guessed a branch wrong (speculation), the instructions executed after the branch must be discarded. Since the Commit Unit hasn't written them to the permanent registers yet, we can simply "flush" the Reorder Buffer to correct the machine state.
{% endstep %}
{% endstepper %}
Hardware Solutions to False Dependencies (WAR & WAW)
The hardware solves these hazards by distinguishing between **Architectural Registers** (visible to software) and **Physical Storage** (internal buffers). This is implicit [**Register Renaming**](#register-renaming).
1. Solving [WAR (Write After Read)](https://wenbo-notes.gitbook.io/ddca-notes/lec/lec-06-advanced-processor#write-after-read-war)
1. **Mechanism: Reservation Stations (RS)**.
2. **How it works**: When an instruction is issued, it **copies** its source operands (or tags) into its specific Reservation Station.
3. **Result**: The instruction now possesses its own local copy of the data. Even if a later instruction overwrites the original architectural register, the pending instruction is unaffected because it no longer reads from the register file.
2. Solving [WAW (Write After Write)](https://wenbo-notes.gitbook.io/ddca-notes/lec/lec-06-advanced-processor#write-after-write-waw)
1. **Mechanism: Commit Unit / Reorder Buffer (ROB)**.
2. **How it works**: Instructions write results to the ROB, not the main register file. The Commit Unit transfers these results to the Architectural Registers strictly in program order.
3. **Result:** Even if a later instruction finishes early, it waits in the ROB. The architectural register is only updated when the instruction officially "commits," ensuring the final value always comes from the logically last instruction.
### Register Renaming
Actually, the out-of-order processors use a technique called **register renaming** to eliminate WAR and WAW hazards. **Register renaming** adds some nonarchitectural renaming registers to the processor. For example, a processor might add 20 renaming registers, called `r0` to `r19`. The programmer cannot use these registers directly, because they are not part of the architecture. However, the processor is free to use them to eliminate hazards.
For example, in the example above, a WAR hazard occurred between the `sub s8, t2, t3` and `add s9, s8, t1` instructions based on reusing `s8`. The out-of-order processor could rename `s8` to `r0` for the `sub` instruction. Then, `sub` could be executed sooner, because `r0` has no dependency on the `add` instruction. The processor keeps a table of which registers were renamed so that it can consistently rename registers in subsequent dependent instructions. In this example, `s8` must also be renamed to `r0` in the `and` instruction, because it refers to the result of `sub`. The following figure shows the same program from [above](#out-of-order-processor) on an out-of-order processor with register renaming.
The constraints on issuing instructions are:
* **Cycle 1**
* The `lw` instruction issues.
* The `add` instruction is dependent on `lw` by way of `s8`, so it cannot issue yet. However, the `sub` instruction is independent now that its destination has been renamed to `r0`, so `sub` also issues.
* **Cycle 2**
* Remember that a two-cycle latency must exist between issuing `lw` and a dependent instruction, so `add` cannot issue yet because of the `s8` dependence.
* The `and` instruction is dependent on `sub`, so it can issue. `r0` is forwarded from `sub` to `and`.
* The `or` instruction is independent, so it also issues.
* **Cycle 3**
* On cycle 3, `s8` is available, so the `add` issues.
* `s11` is also available, so `sw` issues.
Now the out-of-order processor with register renaming issues the six instructions in three cycles, for an IPC of 2, which achieves the [ideal case](#ideal-case)!
Self-Diagnostic Quiz
Perform register renaming to eliminate storage conflicts for the instructions below. Use `a, b, c, ...` to fill in the blanks below, using higher alphabets/names only when necessary. For example, `x1b` should be used only if `x1a` is not sufficient to eliminate the storage conflict.
{% code lineNumbers="true" %}
```riscv
lw x4a, 8(x3a)
sw x3_, (x4_)
add x3_, x3_, x4_
add x4_, x4_, x3_
```
{% endcode %}
***
**Ans**: It is shown as follows
{% code lineNumbers="true" %}
```riscv
lw x4a, 8(x3a)
sw x3a, (x4a)
add x3b, x3a, x4a
add x4b, x4a, x3b
```
{% endcode %}
To solve this kind of question, we use a systematic method called the "**Current Mapping Table**" (or Rename Table) approach, where we simply track the "current" version of every register appeared. And the golden rules to construct this map after each instruction are:
* **Inputs (Reads)**: When an instruction **reads** a register, look at your table and use the **current** letter. Do not **update** the table.
* **Outputs (Writes)**: When an instruction **writes** to a register, give it the **next** letter (increment) and **update** your table immediately.
* *Note:* The output register takes the new name, but the input registers in the *same* instruction use the *old* names.
Using this method, our initial map is **x3: a, x4: a**.
1. sw: As `sw` only reads `x3` and `x4`, both use the a postfix (`x3a`, `x4a`).
2. add (1st): We read the two sources first; both are still a (`x3a`, `x4a`). Then, as `x3` is the destination, we increment it to b (`x3b`).
* *Current Map:* **x3: b, x4: a**
3. add (2nd): We read the sources using the current map: `x4` is still a (`x4a`), but `x3` is now b (`x3b`). Finally, as `x4` is the destination, we increment it from a to b (`x4b`)
* *Current Map:* **x3: b, x4: b**
Thus we can get our final answer!
{% hint style="warning" %}
Instruction like `add x6, x5, x6` has **no hazard** at all!
{% endhint %}
### VLIW Processor
In the above sections, we try to increase the parallelism from the hardware perspective. However, there is a technique that shifts the burden of identifying parallelism from hardware to the compiler. This technique is called **VLIW**.
{% hint style="success" %}
VLIW can be called as **compile-time multiple issue** also.
{% endhint %}
In the VLIW processor, the **compiler** packs groups of independent instructions into the bundle, and the bundle can be thought of as one very long instruction. Hence the name.
Since determining the **order of execution** of operations (including which operations can execute **simultaneously**) is handled by the compiler, the processor does not need the scheduling hardware that the three methods described above require. Thus, VLIW CPUs offer more computing with **less hardware complexity** (but **greater compiler complexity**) than do most superscalar CPUs.
#### VLIW Processor Application
VLIW processors excel in specialized domains like
1. **Digital Signal Processing (DSP)**,
2. **Graphics Processing**, and
3. **Machine Learning**
{% hint style="success" %}
Based on the above three applications, we can know that **VLIW / Compile Time Multiple Issue** is **rarely used** in PC processors or microcontrollers.
{% endhint %}
because these applications rely heavily on repetitive, predictable loops and linear data access patterns. Unlike general-purpose software, these tasks involve very little uncertainty regarding control flow or memory addresses, which minimizes runtime hazards like complex branches or cache misses. This high level of determinism allows the compiler to aggressively optimize and schedule instructions statically, enabling VLIW architectures to achieve high performance without the power-hungry, complex hardware logic needed to handle the unpredictability of mainstream CPUs.
{% hint style="success" %}
Remember the key distinction is **Determinism**. VLIW thrives on static, compile-time predictability (low entropy), whereas Superscalar processors are necessary for high-entropy tasks (like Operating Systems) that require dynamic, runtime adaptability.
{% endhint %}
#### Loop Unrolling
**Loop Unrolling** is a compiler optimization that replicates the loop body multiple times to reduce control overhead (fewer branches and counter updates) and expose larger blocks of independent instructions. For **VLIW processors**, this is critical because it creates a large pool of instructions that can be scheduled in parallel. By unrolling, the compiler can find operations that do not depend on each other (such as the four independent `lw` pairs in the example) and pack them into a single Wide Instruction Word, effectively hiding latency and maximizing the utilization of parallel functional units.
{% hint style="success" %}
You can see the unrolling if you use different compiler flags, like `-O1`, `-O2`, and `-O3`.
{% endhint %}
## Multithreading
> Here, all the stuff will still use one processor!
Multithreading starts from two problems:
1. Because the ILP of real programs tends to be fairly low, adding more execution units to a superscalar or out-of-order processor gives diminishing returns.
2. Memory is much slower than the processor. Most `lw` and `sw` instructions access a much smaller and faster memory called *cache*. However, when the instructions or data are not available in the cache, the processor may stall for 100 or more cycles while retrieving the information from the main memory.
**Multithreading** is a technique that helps keep a processor with many execution units busy even if
1. the ILP of a program is low or
2. the program is stalled waiting for memory
To explain multithreading, we need to define two new terms
{% stepper %}
{% step %}
#### Process
A program running on a computer is called a **process**. Computers can run **multiple processes simultaneously**. For example, you can play music on a PC while surfing the web and running a virus checker.
Also, if you click the icon to run a program on your PC. After clicking, the programming is running. And after the program is loaded into the memory, it is called **process**.
{% endstep %}
{% step %}
#### Thread
Each **process** consists of one or more **threads** that also run "simultaneously". For example, a word processor may have one thread handling the user typing, a second thread spell-checking the document while the user works, and a third thread printing the document. In this way, the user does not have to wait, for example, for a document to finish printing before being able to type again.
The degree to which a process can be split into multiple threads that can run "simultaneously" defines its level of **thread-level parallelism (TLP)**.
How to create threads from a process?
The threads are usually created by the programmer himself. In C, you may use `pthread` (this has appeared in the [CG2111A project](https://github.com/mendax1234/CG2111A-Final-Project/blob/1c5f6b52bcfc5b8db2f738e75056d1e6061ed927/RPi/alex-pi.cpp#L494)) to create a thread manually. In Java, we can do so using the `Thread` class (this has appeared in [CS2030S](https://wenbo-notes.gitbook.io/cs2030s-notes/lec-rec-lab-exes/lecture/lec-11-parallelization-and-asynchronous#create-a-thread)). In whichever way, the spirit is that threads are usually created by the programmer.
{% endstep %}
{% endstepper %}
**Multithreading** (whether software or hardware) lets **one processor** appear to do **multiple things at once**.
### Software Multithread
In a conventional processor, the threads only give the illusion of running simultaneously. The threads actually take turns being executed on the processor under control of the operating system (OS). When one thread’s turn ends, the OS saves its architectural state, loads the architectural state of the next thread, and starts executing that next thread. This procedure is called **context switching**. As long as the processor switches through all threads fast enough, the user perceives all of the threads as running at the same time.
Usually, there are ways for the context switching to happen in this scenario:
{% stepper %}
{% step %}
#### Co-operative Multitasking
In this case, the context switch happens when **one thread stalls**. The next thread to be run is determined by the OS scheduler.
{% endstep %}
{% step %}
#### Preemptive Multitasking
The context switch can be initiated through **timer interrupts**, without having to wait for the thread to stall.
{% endstep %}
{% endstepper %}
{% hint style="success" %}
This describes the **software-based concurrency** on a **single-core CPU**.
{% endhint %}
### Hardware Multithread
A **hardware multithreaded** processor contains more than one copy of its architectural state so that more than one thread can be active at a time.
For example, if we extended a processor to have four program counters and 128 registers, four threads could be available at one time. If one thread stalls while waiting for data from main memory, then the processor could context switch to another thread **without any delay**, because the program counter and registers are already available. Moreover, if one thread lacks sufficient parallelism to keep all execution units busy in a superscalar design, then another thread could issue instructions to the idle units.
Switching between threads can either be **fine-grained** or **coarse-grained**.
{% stepper %}
{% step %}
#### Fine-grained multithreading
**Fine-grained multithreading** switches between threads on each instruction and must be supported by hardware multithreading.
The advantage for fine-grained multithreading is that there will be less control and data hazards. As each thread is independent and now the total number of stages is splited into two threads running, thus having less control and data hazards overall.
{% hint style="success" %}
This is **temporal**.
{% endhint %}
{% endstep %}
{% step %}
#### Coarse-grained multithreading
**Coarse-grained multithreading** switches out a thread only on expensive stalls, such as long memory accesses due to cache misses.
{% hint style="success" %}
This is **temporal**.
{% endhint %}
{% endstep %}
{% step %}
#### Simultaneous multithreading
This is also know as SMT or hyperthreading (called by Intel). If one thread can't keep all execution units busy, another thread can use them, so instructions from different threads execute at the same time, without duplication of functional units.
{% hint style="success" %}
This is both **temporal** and **spatial**.
{% endhint %}
{% endstep %}
{% endstepper %}
Multithreading does not improve the performance of an individual thread, because it does not increase the ILP. However, it does improve the overall **throughput** of the processor, because multiple threads can use processor resources that would have been idle when executing a single thread.
### Flynn's Taxonomy
There are four types of computer architectures in the Flynn's Taxonomy, we will introduce them one by one and give you some concrete examples for each of them.
#### Single Instruction stream Single Data stream (SISD)
It's essentially a sequential computer which exploits no parallelism in either the instruction or data stream.
One example is a single-thread or single-core processor.
#### Single Instruction stream Multiple Data streams (SIMD)
It's a computer which exploits multiple data streams against a single instruction stream to perform operations which may be naturally parallelized.
* Exploits **data parallelism**
The examples are **hardware accelerators** and **GPU**s.
#### Multiple Instruction streams Single Data stream (MISD)
As its name suggests, it's multiple instructions operating on one data stream.
This is an uncommon architecture and the examples are **autopilot** system of the aeroplane, and the **systolic arrays** which are the heart of Google TPUs.
#### Multiple Instruction streams Multiple Data streams (MIMD)
Multiple autonomous processors simultaneously executing different instructions on different data.
* Exploits thread-level/task parallelism
The examples of MIMD architectures include **parallel /** **distributed systems**, using either one shared memory space or a distributed memory space.
Why multithreading is considered as MIMD?
Whenever a thread is created by the programmer, a **new instruction stream** is created. Usually, threads are independent from each other except that they may share the same memory. As each thread operates on its own data, thus we have multiple instruction streams and multiple data streams in multithreading.
## Multiprocessors
Modern processors have enormous numbers of transistors available. Using them to increase the pipeline depth or to add more execution units to a [superscalar processor](#superscalar-processors) gives little performance benefit and wastes power. Around the year 2005, computer architects made a major shift to building multiple copies of the processor on the same chip; these copies are called **cores**.
A multiprocessor system consists of multiple processors and a method for communication between the processors. This system can be divided into two categories based on **whether it has a shared memory at any level**:
1. [Loosely Coupled Multiprocessor Systems](#loosely-coupled-mutiprocessor-systems), and
2. [Tightly Coupled Multiprocessor Systems](#tightly-coupled-mutiprocessor-systems)
### Loosely Coupled Mutiprocessor Systems
In this system, each node runs different OS instances and communicate by **passing messages** rather than through a shared memory. In this kind of system, we have two concrete examples:
1. [Computer Clusters](#clusters)
2. [Grid Computers](#grid-computers)
#### Clusters
In a **clustered multiprocessor** system, each processor has its own local memory system instead of sharing memory.
It has the nodes set to perform the same task, controlled and scheduled by software. These nodes are typically **hemogenous in hardware and software,** housed in the same building / geography, interconnected using a dedicated network, and have shared resources. This system is often viewed as a single computer from outside, but it actually has a lot of nodes (small computers) inside.
One example is the **supercomputer**.
#### Grid Computers
This system is **very loosely coupled**, which means **diverse computers/nodes** are connected via internet and they are geographically dispersed.
Within this system, each node performs a different task to reach a common goal. The nodes are typically heterogenous in hardware and autonomous in software.
One example is the **cryptocurrency mining tools**.
### Tightly Coupled Mutiprocessor Systems
Tightly coupled multiprocessor systems are usually mounted on the same mother board or within the same silicon die, communicates via **shared memory** and usually controlled by a single OS.
In this system, as you can see from the image above
* Each processor executes different programs and works on different data
* Each processor usually has one or more levels of private cache
* The processors share many resouces (e.g., higher level caches, memory, I/O device, interrupt system, etc.)
* All processors are connected using a system bus.
However, for all the processors to communicate smoothly via the share memory, some mechanisms are needed to handle the conflict
1. **Arbitration mechanisms**: If two processors attempt to use the same resource **simultaneously**, this mechanism is needed to deal with this situation.
2. **Mutual exclusion mechanisms**: This is used to protect resources (or a range of memory) which should not be used in a **concurrent** manner.
3. **Cache coherence ensurance mechanisms**: This is to ensure the cache coherence across all levels.
1. **Bus snooping** and **directory-based mechanisms** are two examples.
In the tightly coupled multiprocessor system, we have two small parts
1. [Symmetric Multiprocessors](#symmetric-multiprocessors)
2. [Heterogeneous Multiprocessors](#heterogeneous-multiprocessors)
{% hint style="success" %}
Multiprocessors can be used to do the following two things:
1. run more threads simultaneously, or
2. run a particular thread faster
{% endhint %}
#### Symmetric Multiprocessors
**Symmetric multiprocessors** (SMP) include two or more **identical processors** sharing a single main memory. The multiple processors may be separate chips or multiple cores on the same chip. For example, Intel Core i3, i5 (prioir to Alder Lake) etc.
{% hint style="success" %}
Symmetric multiprocessors are good for situations like large data centers that have lots of thread-level parallelism available.
{% endhint %}
#### Heterogeneous Multiprocessors
**Heterogeneous multiprocessors** (HMP) incorporate different types of cores and/or specialized hardware in a single system. And it can take the following two forms:
1. a heterogeneous system can incorporate cores with the same architecture but different microarchitectures, each with different power, performance, and area trade-offs.
2. another heterogeneous strategy is **accelerators**, in which a system contains special-purpose hardware optimized for performance or energy efficiency on specific types of tasks.
{% hint style="success" %}
Heterogeneous systems are good for systems that have more varying or special-purpose workloads, such as mobile devices.
{% endhint %}
Multithread and multiprocessor in real world
In real world, when the programmner writes a high level program and creates some threads in the program. He doesn't care whether this program will be run on a single processor or a muliprocessor system. The final outcome will be the same. But how it is executed may be different
1. If the process is executed on a single processor, the processor may perform the multithreading techniques to switch between threads to achieve the fact that multiple threads are executed simultaneously.
2. If the process is executed on a multiprocessor system, the threads can run inherently in parallel as multiple processors are available.
Let's look at some real world examples for the heterogenous multiprocessor system!
#### ARM big.LITTE
ARM **big.LITTLE** is a heterogeneous computing architecture coupling relatively battery-saving and slower processor cores (LITTLE) with relatively more powerful and power-hungry ones (big). It has the following 3 variants:
{% stepper %}
{% step %}
#### Clustered switching
This is the simplest implementation that arranges the processor into identically-sized **clusters** of **big** or **LITTLE** cores. The scheduler will pick one cluster and all the processors in that cluster will be enabled.
{% endstep %}
{% step %}
#### In-kernal switcher
In this paradigm, each big core is paired up with a small core into a "virtual core". As these "virtual cores" are the same, thus it forms a Symmetric Multiprocessor system (SMP). The scheduler can assign any thread to any one of the virtual in the SMP.
{% endstep %}
{% step %}
#### Global task scheduling
This is the most powerful and popluar paradigm currently, as it can enable all physical cores at the same time. In this paradigm, the "burden" will go to the scheduler.
Within the scheduler, threads with high priority or computational intensity are allocated to the **big** cores, while threads with lower priority or less computational intensity, such as background tasks, can be performed by the **LITTLE** cores.
Apple A14 uses this paradigm and it has 11.8 billion transistors in total!
{% endstep %}
{% endstepper %}
## SIMD/Vector Processing
> Our motivation here is the **amortization**.
In standard processors, every instruction incurs significant overhead because fetching and decoding commands consumes both power and time. If a program needs to perform the same operation on multiple data points — such as adding eight pairs of numbers — standard CPU wastes effort by fetching and decoding the "Add" command eight separate times. The solution is SIMD, which allows the processor to fetch and decode the command just once and apply it to all data points simultaneously. This strategy effectively "amortizes," or spreads out, the expensive management costs across many data elements to improve efficiency.
### Packed SIMD
This first option places the control explicitly in the hands of the software. The programmer must intentionally use special vector instructions (e.g., `VEC8_mul`) to define how data is packed and processed. While this course treats the following two terms similarly, there is a nuance in terminology:
* **Packed SIMD**: Refers to fixed-width registers (e.g., "Process exactly 4 items at once"). This is common in standard CPUs like Intel AVX or ARM NEON.
* **Vector Processing**: Often implies variable-length processing (e.g., "Process a list of *n* items"). This is common in supercomputers or RISC-V Vector extensions.
### GPU
The second option, used by GPUs, shifts the complexity from the programmer to the hardware. This is often called SIMT (Single Instruction, Multiple Threads). Instead of writing complex vector code, the programmer writes standard scalar instructions (like a simple `mul`) intended for a single thread. The GPU hardware then performs the vectorization automatically:
* **Implicit Grouping**: The hardware dynamically bundles these individual threads into groups (called "Warps" by NVIDIA or "Wavefronts" by AMD).
* **Lockstep Execution**: These bundles are then executed on the hardware's SIMD units in lockstep.
This allows the programmer to think in terms of simple, single threads, while the hardware ensures the massive throughput of vector processing.
## Systolic Arrays
> Our motivation here is to **eliminate memory bottleneck**.
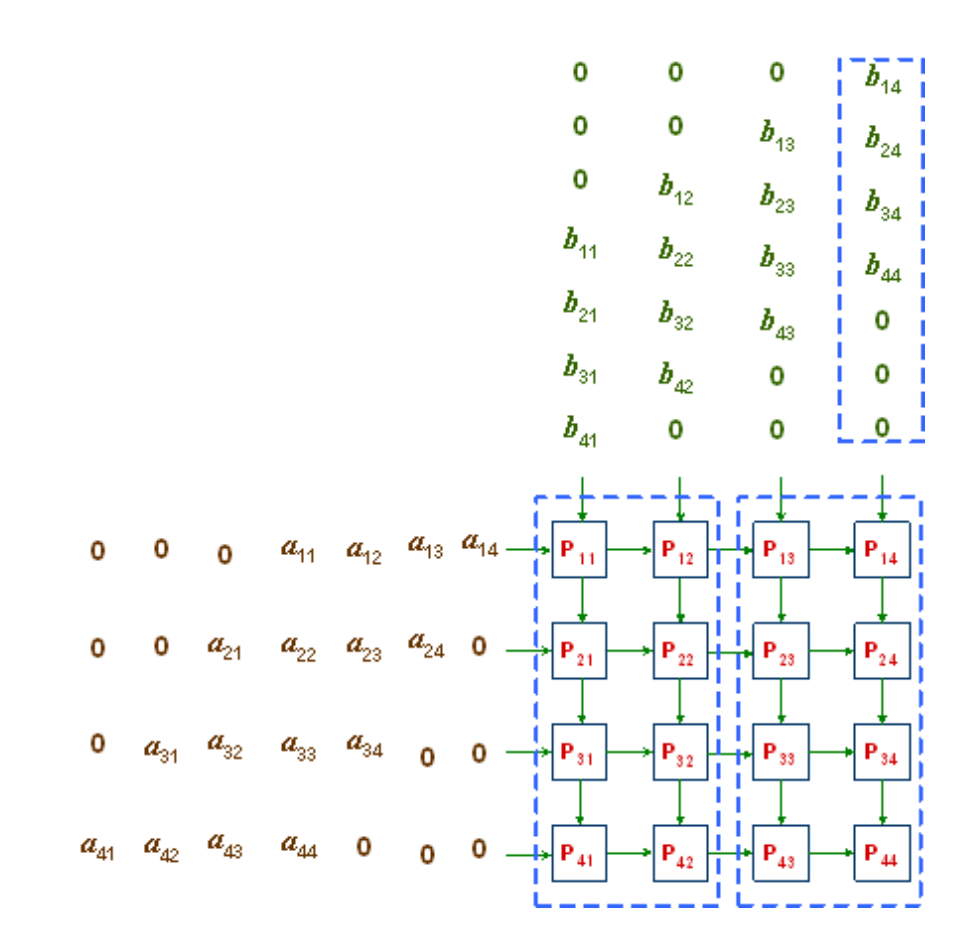
In standard processors (like the [SIMD](#simd-vector-processing) examples we discussed), data is frequently read from memory, processed, and written back. This constant access to memory (registers or cache) creates a bottleneck. The **Systolic Array** solves this by mimicking the rhythm of a beating heart ("systole"). Instead of each processor acting independently, they form a tightly coupled network. Data flows from memory into the array once and is then rhythmically passed from neighbor to neighbor.
Its main mechanism is called **Rhythmic Data Flow**. A systolic array consists of a grid of Processing Elements (PEs). Data flows through the array in a wave-like fashion. When a PE finishes a calculation, it passes the data directly to its neighbor rather than writing it back to memory.
* The **Trade-off**: This design sacrifices flexibility (it is hard to do general-purpose logic like "If/Else") and limits available registers.
* The **Reward**: In exchange, it achieves immense efficiency for specific tasks like Matrix Multiplication. Since operand data and partial results are stored *within* the passing wave, the system drastically reduces the need to access external buses or caches, saving power and increasing operation density.
### TPU
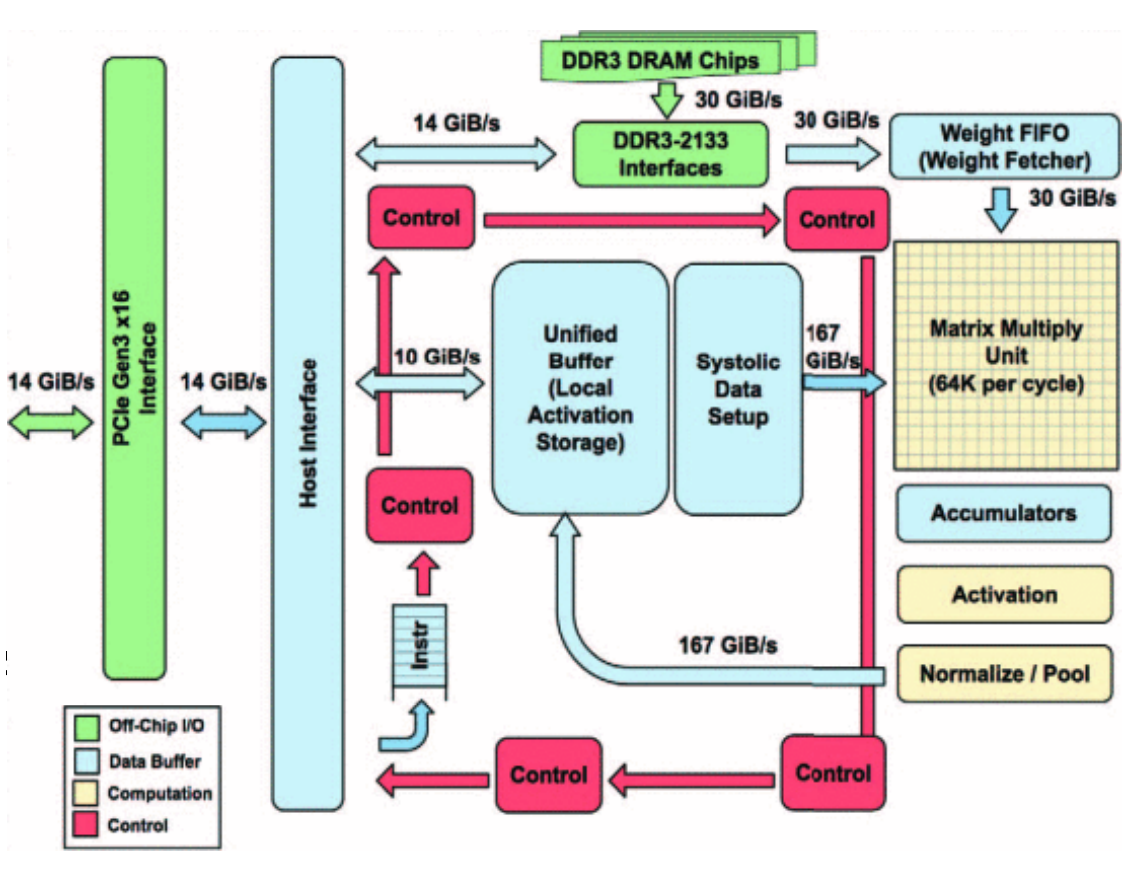
One application of the **systolic array** is the Google TPU. The Google Tensor Processing Unit (TPU) v1 is a real-world implementation of a systolic array, designed specifically for heavy compute workloads like Machine Learning inference. It is not a standalone CPU; it sits on a PCIe bus and acts as a coprocessor, receiving instructions from a host CPU. Because the TPU runs massive, complex tasks (like multiplying two huge matrices) with a single command, it utilizes a CISC instruction set.
The heart of the TPU is the Matrix Multiply Unit, a massive $$256 \times 256$$ systolic array containing over 65,000 processing units.
* **Data Flow**: It reads in weights and data (activations) into local buffers (Weight FIFO and Unified Buffer). These values flow through the Matrix Unit, performing 8-bit multiply-accumulate operations at a rate of up to 92 Tera-operations per second.
* **Pipeline**: The results flow out to an Activation Unit (which applies hardwired functions like ReLU) and can be fed back into the Unified Buffer for the next layer of calculation. This design creates a pipeline optimized entirely for the math required by deep neural networks.
[^1]: Sometimes, BHT is called **branch prediction buffer**.
[^2]: this is mainly to reduce the propagation delay within the logic gates, so the same logic gate that built with the advanced manufacturing technology will have a **smaller** propagation delay.
[^3]: In short, there are three dependencies here:
1. Read after Write (RAW)
2. Write after Read (WAR)
3. Write after Write (WAW)